

728x90
💡
Today I Learned 요약 (32회차)
- 재해 복구 관련 AWS에서는 복구시점(RPO)와 복구시간(RTO)를 정의하고 이에 맞춰 DR 전략을 수립할 것을 권고하고 있다.
- 다중 동기화/복원이 많을 수록 워크로드는 안정되지만 그만큼 비용이 급상승하게 된다.
AWS 재해복구(DR) 관련 단어 메모
카카오 서비스 셧다운 쯤해서 나도 재해복구(Disaster Recovery)에 대해 보다 관심을 가지게 되었다. 있을 순 있지만 남일이라고 생각하고 있었다는 게 적절할 것 같다. 실제로 겪어본 적도 없고… 하지만 카카오가 당하는 걸 보면서 나도 관련 개념에 대해 이해할 필요가 있다고 느껴서 메모를 정리하게 되었다.
우선 AWS의 재해복구 관련 문서를 찾아보고 관련 단어(개념)들에 대해 메모해두려고 한다.
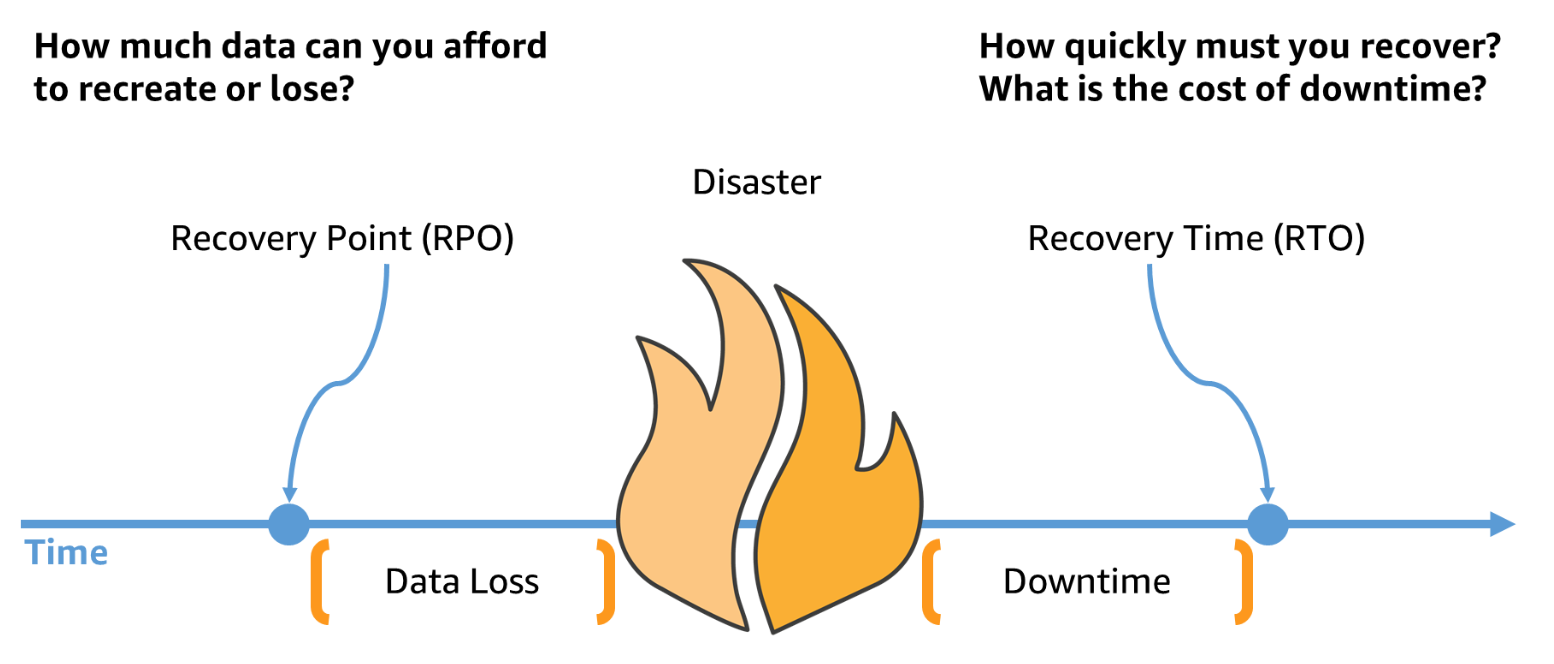
AWS에서는 재해 발생 시각을 전후로 복구시점(RPO)와 복구시간(RTO)을 정의하고 있다.
- 복구시점(RPO - Recovery Point Objective)
- 서비스 중단 시점과 서비스 복원 시점 간에 허용되는 최대 지연 시간으로, 서비스를 사용할 수 없는 상태로 허용되는 기간
- 복구시간(RTO - Recovery Time Objective)
- 마지막 데이터 복구 시점 이후 허용되는 최대 시간으로, 마지막 복구 시점과 서비스 중단 시점 사이에 허용되는 데이터 손실량
위 2가지는 낮을 수록 좋지만 낮게 잡으면 잡을수록 비용은 급속도로 증가하게 된다. 따라서 각자 상황에 따라 RPO와 RTO를 커스텀하게 정의하게 된다. 설정된 RTO와 RPO에 따라 선택할 수 있는 재해복구 전략으로 AWS는 4가지를 소개하고 있다.
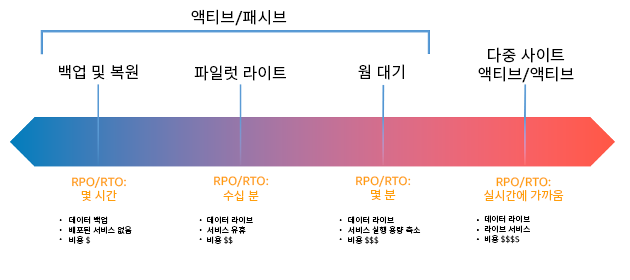
- 백업 및 복원
- 스냅샷 느낌으로 ‘복구 리전’에 데이터와 애플리케이션을 백업해놓고 재해 발생시 최종 스냅샷을 복구하는 것
- 파일럿 라이트(pilot light)
- 코어 서비스의 복사본을 별도의 복구 리전에 프로비저닝하는 것. 데이터 역시 복구 리전에 복제된다. 백업을 위한 자원을 계속해서 동작 상태로 유지된다.
- 웜 대기(worm standBy)
- 모든 기능이 동일하지만 축소된 버전의 워크로드를 복구 리전에서 상시 실행중인 상태로 유지하는 상태. 재해 발생시 축소된 워크로드가 프로덕션 환경을 대체하게 되며 웜 대기가 확대될 수록 RTO는 낮아지게 됨
- 복수 리전 액티브
- 워크로드가 동시에 여러 리전에 배포되고 능동적을로 트래픽이 처리됨. 해당 전략을 사용하려면 리전 전체에서 데이터 및 어플리케이션 동기화가 이뤄져야 함. 서로 다른 리전에서 복제본에 동일 레코드 값을 쓸 수 있는 충돌을 처리해야 하는데 해당 문제가 복잡할 수 있음. 가장 유용하지만 가장 비용이 많이 발생함.
AWS 관련 리서치한 것:
728x90
'CLOUD' 카테고리의 다른 글
| [TIL] 도커 워드프레스 및 레드마인 실행 연습 (0) | 2022.11.21 |
|---|---|
| [TIL] 도커로 워드프레스 실행하기 (0) | 2022.11.15 |
| [TIL] Docker 이미지 삭제하기 (0) | 2022.11.14 |
| [TIL] 도커 포트 번호 설정하기 221109 (0) | 2022.11.10 |
| [TIL] Docker 기본 실행 명령어 221108 (0) | 2022.11.08 |
| [TIL] AWS CLI s3 sync를 사용하여 파일 전송하기 221028 (0) | 2022.10.28 |